CauseClusterer and EffectClusterer Hyperparameter Tuning
This notebook gives a quick demo of how to tune a CauseClusterer and/or EffectClusterer directly through CFL parameter specification.
[1]:
import numpy as np
from sklearn.model_selection import train_test_split
import visual_bars.generate_visual_bars_data as vbd
from cfl.experiment import Experiment
Load Data
We will be using the visual bars example data for this tutorial. To learn more about this included dataset, please refer to the visual bars background page. If you would like to see a standard example of running CFL on this dataset without hyperparameter tuning, please refer to the main CFL code tutorial.
Here, we create a dataset of 10000 samples, where the cause is a 10x10 image and the effect is a binary 1D variable. For sake of simplicity, we will be tuning a standard feed-forward network (as opposed to a convolutional neural network), so flatten the images down to vectors of shape (1,100).
Since we want to evaluate our models on the same subset of the data across all hyperparameter combinations, we generate in-sample and out-of-sample indices to pass to CFL. If these are not provided, CFL generates this split randomly, and it would look different across every trial.
[2]:
# create visual bars data
n_samples = 10000
im_shape = (10, 10)
noise_lvl= 0.03
random_state = 180
vb_data = vbd.VisualBarsData(n_samples=n_samples, im_shape=im_shape,
noise_lvl=noise_lvl, set_random_seed=random_state)
# retrieve the images and the target
X = vb_data.getImages()
X = np.reshape(X, (X.shape[0], np.product(X.shape[1:]))) # flatten images
Y = vb_data.getTarget()
Y = np.expand_dims(Y, -1)
print(X.shape)
print(Y.shape)
# define train and validation sets to remain constant across tuning
in_sample_idx, out_sample_idx = train_test_split(np.arange(X.shape[0]),
train_size=0.75,
random_state=42)
(10000, 100)
(10000, 1)
Set up CFL pipeline
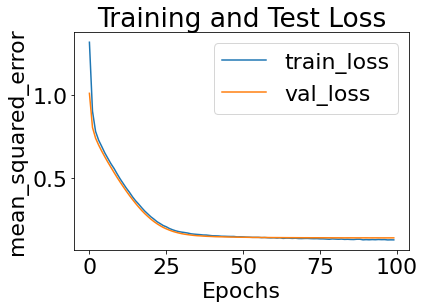
Here, we assume we have already tuned the CDE and will focus on tuning the CauseClusterer (as can be seen from the loss plot below, this assumption is very wrong). The CauseClusterer expects the user to specify the 'model’ they would like to use (usually an sklearn model), along with any associated hyperparameters they would like to specify through a model_params dict:
CauseClusterer_params = {'model' : 'DBSCAN', # sklearn model
'model_params' : {
'eps' : 0.1, # dbscan hyperparam
'min_samples : 10}, # dbscan hyperparam
'verbose' : 0, # CFL verbosity setting
'tune' : False # default is False
}
This syntax can be extended to tune the clusterer over a range of hyperparameters by making all model parameters iterable:
CauseClusterer_params = {'model' : ['DBSCAN'], # sklearn model (formatted
# as list for compatibility)
'model_params' : {
'eps' : np.logspace(-5,2,10), # try 10 values of `eps`
'min_samples : np.linspace(10,60,5)}, # try 5 values of `min_samples`
'verbose' : 0 # CFL verbosity setting (does
# not need to be iterable because
# filtered out as cfl param)
'tune' : True # default is False
}
[5]:
# the parameters should be passed in dictionary form
data_info = {'X_dims' : X.shape,
'Y_dims' : Y.shape,
'Y_type' : 'categorical' #options: 'categorical' or 'continuous'
}
# the optimal hyperparameters for the CDE can be found by following the
# Optuna tuning tutorial
CDE_params = { 'model' : 'CondExpMod',
'model_params' : {
'dense_units' : [160, data_info['Y_dims'][1]],
'activations' : ['relu', 'linear'],
'dropouts' : [0.1, 0],
'kernel_regularizers' : [None] * 2,
'bias_regularizers' : [None] * 2,
'activity_regularizers' : [None] * 2,
'batch_size' : 72,
'n_epochs' : 100,
'optimizer' : 'adam',
'opt_config' : {'lr' : 4e-05},
'loss' : 'mean_squared_error',
'best' : True,
'verbose' : 1}
}
# CauseClusterer_params = {'model' : 'DBSCAN',
# 'model_params' : {
# 'eps' : np.logspace(-3.5,-1,15),
# 'min_samples' : np.arange(30,300,30).astype(int)},
# 'verbose' : 1,
# 'tune' : True
# }
CauseClusterer_params = {'model' : 'KMeans',
'model_params' : {
'n_clusters' : np.arange(2,11).astype(int)},
'verbose' : 1,
'tune' : True
}
# steps of this CFL pipeline
block_names = ['CondDensityEstimator', 'CauseClusterer']
block_params = [CDE_params, CauseClusterer_params]
# folder to save results to
save_path = 'visual_bars_cfl'
# create the experiment!
my_exp = Experiment(X_train=X,
Y_train=Y,
data_info=data_info,
block_names=block_names,
block_params=block_params,
results_path=save_path)
All results from this run will be saved to visual_bars_cfl/experiment0017
Block: verbose not specified in input, defaulting to 1
CondExpBase: kernel_initializers not specified in input, defaulting to None
CondExpBase: bias_initializers not specified in input, defaulting to None
CondExpBase: weights_path not specified in input, defaulting to None
CondExpBase: show_plot not specified in input, defaulting to True
CondExpBase: tb_path not specified in input, defaulting to None
CondExpBase: optuna_callback not specified in input, defaulting to None
CondExpBase: optuna_trial not specified in input, defaulting to None
CondExpBase: early_stopping not specified in input, defaulting to False
CondExpBase: checkpoint_name not specified in input, defaulting to tmp_checkpoints
Block: user_input not specified in input, defaulting to True
[6]:
train_results = my_exp.train()
#################### Beginning CFL Experiment training. ####################
Beginning CondDensityEstimator training...
No GPU device detected.
Epoch 1/100
WARNING:tensorflow:AutoGraph could not transform <function Model.make_train_function.<locals>.train_function at 0xf1fc38ef0> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: 'arguments' object has no attribute 'posonlyargs'
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function Model.make_train_function.<locals>.train_function at 0xf1fc38ef0> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: 'arguments' object has no attribute 'posonlyargs'
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
104/105 [============================>.] - ETA: 0s - loss: 1.3172WARNING:tensorflow:AutoGraph could not transform <function Model.make_test_function.<locals>.test_function at 0x1a53234320> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: 'arguments' object has no attribute 'posonlyargs'
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function Model.make_test_function.<locals>.test_function at 0x1a53234320> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: 'arguments' object has no attribute 'posonlyargs'
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
105/105 [==============================] - 3s 11ms/step - loss: 1.3166 - val_loss: 1.0101
Epoch 2/100
105/105 [==============================] - 1s 6ms/step - loss: 0.9030 - val_loss: 0.8055
Epoch 3/100
105/105 [==============================] - 0s 5ms/step - loss: 0.7817 - val_loss: 0.7412
Epoch 4/100
105/105 [==============================] - 1s 6ms/step - loss: 0.7290 - val_loss: 0.6998
Epoch 5/100
105/105 [==============================] - 1s 5ms/step - loss: 0.6916 - val_loss: 0.6633
Epoch 6/100
105/105 [==============================] - 1s 7ms/step - loss: 0.6529 - val_loss: 0.6295
Epoch 7/100
105/105 [==============================] - 1s 6ms/step - loss: 0.6201 - val_loss: 0.5971
Epoch 8/100
105/105 [==============================] - 0s 4ms/step - loss: 0.5878 - val_loss: 0.5661
Epoch 9/100
105/105 [==============================] - 0s 4ms/step - loss: 0.5597 - val_loss: 0.5354
Epoch 10/100
105/105 [==============================] - 1s 6ms/step - loss: 0.5273 - val_loss: 0.5058
Epoch 11/100
105/105 [==============================] - 0s 3ms/step - loss: 0.4965 - val_loss: 0.4775
Epoch 12/100
105/105 [==============================] - 1s 6ms/step - loss: 0.4689 - val_loss: 0.4501
Epoch 13/100
105/105 [==============================] - 0s 3ms/step - loss: 0.4414 - val_loss: 0.4234
Epoch 14/100
105/105 [==============================] - 1s 6ms/step - loss: 0.4170 - val_loss: 0.3978
Epoch 15/100
105/105 [==============================] - 0s 4ms/step - loss: 0.3897 - val_loss: 0.3736
Epoch 16/100
105/105 [==============================] - 0s 5ms/step - loss: 0.3658 - val_loss: 0.3501
Epoch 17/100
105/105 [==============================] - 0s 3ms/step - loss: 0.3458 - val_loss: 0.3283
Epoch 18/100
105/105 [==============================] - 0s 3ms/step - loss: 0.3241 - val_loss: 0.3075
Epoch 19/100
105/105 [==============================] - 0s 5ms/step - loss: 0.3038 - val_loss: 0.2886
Epoch 20/100
105/105 [==============================] - 1s 6ms/step - loss: 0.2865 - val_loss: 0.2714
Epoch 21/100
105/105 [==============================] - 0s 3ms/step - loss: 0.2692 - val_loss: 0.2551
Epoch 22/100
105/105 [==============================] - 0s 4ms/step - loss: 0.2552 - val_loss: 0.2406
Epoch 23/100
105/105 [==============================] - 1s 6ms/step - loss: 0.2398 - val_loss: 0.2276
Epoch 24/100
105/105 [==============================] - 1s 8ms/step - loss: 0.2288 - val_loss: 0.2160
Epoch 25/100
105/105 [==============================] - 1s 6ms/step - loss: 0.2171 - val_loss: 0.2057
Epoch 26/100
105/105 [==============================] - 1s 7ms/step - loss: 0.2093 - val_loss: 0.1971
Epoch 27/100
105/105 [==============================] - 1s 8ms/step - loss: 0.1993 - val_loss: 0.1895
Epoch 28/100
105/105 [==============================] - 1s 6ms/step - loss: 0.1919 - val_loss: 0.1826
Epoch 29/100
105/105 [==============================] - 1s 6ms/step - loss: 0.1857 - val_loss: 0.1771
Epoch 30/100
105/105 [==============================] - 1s 7ms/step - loss: 0.1809 - val_loss: 0.1723
Epoch 31/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1774 - val_loss: 0.1682
Epoch 32/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1748 - val_loss: 0.1648
Epoch 33/100
105/105 [==============================] - 0s 5ms/step - loss: 0.1719 - val_loss: 0.1622
Epoch 34/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1675 - val_loss: 0.1598
Epoch 35/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1654 - val_loss: 0.1577
Epoch 36/100
105/105 [==============================] - 1s 5ms/step - loss: 0.1638 - val_loss: 0.1561
Epoch 37/100
105/105 [==============================] - 0s 2ms/step - loss: 0.1623 - val_loss: 0.1550
Epoch 38/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1602 - val_loss: 0.1536
Epoch 39/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1599 - val_loss: 0.1525
Epoch 40/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1578 - val_loss: 0.1518
Epoch 41/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1556 - val_loss: 0.1510
Epoch 42/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1551 - val_loss: 0.1500
Epoch 43/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1544 - val_loss: 0.1496
Epoch 44/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1527 - val_loss: 0.1492
Epoch 45/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1525 - val_loss: 0.1486
Epoch 46/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1518 - val_loss: 0.1483
Epoch 47/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1513 - val_loss: 0.1478
Epoch 48/100
105/105 [==============================] - 1s 5ms/step - loss: 0.1514 - val_loss: 0.1476
Epoch 49/100
105/105 [==============================] - 1s 6ms/step - loss: 0.1490 - val_loss: 0.1472
Epoch 50/100
105/105 [==============================] - 0s 2ms/step - loss: 0.1492 - val_loss: 0.1467
Epoch 51/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1487 - val_loss: 0.1466
Epoch 52/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1475 - val_loss: 0.1465
Epoch 53/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1470 - val_loss: 0.1461
Epoch 54/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1460 - val_loss: 0.1457
Epoch 55/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1461 - val_loss: 0.1455
Epoch 56/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1461 - val_loss: 0.1454
Epoch 57/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1445 - val_loss: 0.1452
Epoch 58/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1452 - val_loss: 0.1450
Epoch 59/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1436 - val_loss: 0.1451
Epoch 60/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1429 - val_loss: 0.1449
Epoch 61/100
105/105 [==============================] - 1s 7ms/step - loss: 0.1436 - val_loss: 0.1447
Epoch 62/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1419 - val_loss: 0.1446
Epoch 63/100
105/105 [==============================] - 1s 5ms/step - loss: 0.1432 - val_loss: 0.1445
Epoch 64/100
105/105 [==============================] - 0s 5ms/step - loss: 0.1398 - val_loss: 0.1443
Epoch 65/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1414 - val_loss: 0.1442
Epoch 66/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1411 - val_loss: 0.1441
Epoch 67/100
105/105 [==============================] - 0s 2ms/step - loss: 0.1397 - val_loss: 0.1441
Epoch 68/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1410 - val_loss: 0.1440
Epoch 69/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1390 - val_loss: 0.1439
Epoch 70/100
105/105 [==============================] - 0s 5ms/step - loss: 0.1387 - val_loss: 0.1438
Epoch 71/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1395 - val_loss: 0.1437
Epoch 72/100
105/105 [==============================] - 0s 2ms/step - loss: 0.1397 - val_loss: 0.1438
Epoch 73/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1384 - val_loss: 0.1436
Epoch 74/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1379 - val_loss: 0.1437
Epoch 75/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1382 - val_loss: 0.1437
Epoch 76/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1370 - val_loss: 0.1436
Epoch 77/100
105/105 [==============================] - 1s 7ms/step - loss: 0.1369 - val_loss: 0.1436
Epoch 78/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1359 - val_loss: 0.1435
Epoch 79/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1346 - val_loss: 0.1435
Epoch 80/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1367 - val_loss: 0.1434
Epoch 81/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1357 - val_loss: 0.1432
Epoch 82/100
105/105 [==============================] - 0s 5ms/step - loss: 0.1347 - val_loss: 0.1433
Epoch 83/100
105/105 [==============================] - 1s 6ms/step - loss: 0.1357 - val_loss: 0.1432
Epoch 84/100
105/105 [==============================] - 1s 7ms/step - loss: 0.1338 - val_loss: 0.1431
Epoch 85/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1346 - val_loss: 0.1432
Epoch 86/100
105/105 [==============================] - 1s 7ms/step - loss: 0.1334 - val_loss: 0.1432
Epoch 87/100
105/105 [==============================] - 1s 6ms/step - loss: 0.1330 - val_loss: 0.1431
Epoch 88/100
105/105 [==============================] - 1s 5ms/step - loss: 0.1348 - val_loss: 0.1430
Epoch 89/100
105/105 [==============================] - 0s 4ms/step - loss: 0.1348 - val_loss: 0.1430
Epoch 90/100
105/105 [==============================] - 1s 6ms/step - loss: 0.1312 - val_loss: 0.1431
Epoch 91/100
105/105 [==============================] - 1s 6ms/step - loss: 0.1324 - val_loss: 0.1432
Epoch 92/100
105/105 [==============================] - 1s 6ms/step - loss: 0.1315 - val_loss: 0.1429
Epoch 93/100
105/105 [==============================] - 0s 5ms/step - loss: 0.1327 - val_loss: 0.1430
Epoch 94/100
105/105 [==============================] - 1s 6ms/step - loss: 0.1318 - val_loss: 0.1430
Epoch 95/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1332 - val_loss: 0.1430
Epoch 96/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1323 - val_loss: 0.1428
Epoch 97/100
105/105 [==============================] - 0s 2ms/step - loss: 0.1327 - val_loss: 0.1429
Epoch 98/100
105/105 [==============================] - 0s 2ms/step - loss: 0.1307 - val_loss: 0.1428
Epoch 99/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1312 - val_loss: 0.1429
Epoch 100/100
105/105 [==============================] - 0s 3ms/step - loss: 0.1309 - val_loss: 0.1430
WARNING:tensorflow:AutoGraph could not transform <function Model.make_predict_function.<locals>.predict_function at 0x1a53234a70> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: 'arguments' object has no attribute 'posonlyargs'
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function Model.make_predict_function.<locals>.predict_function at 0x1a53234a70> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: 'arguments' object has no attribute 'posonlyargs'
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
0it [00:00, ?it/s]
Loading parameters from tmp_checkpoints01042022185134/best_weights
Saving parameters to visual_bars_cfl/experiment0017/trained_blocks/CondDensityEstimator
CondDensityEstimator training complete.
Beginning CauseClusterer training...
Beginning clusterer tuning
9it [00:06, 1.46it/s]
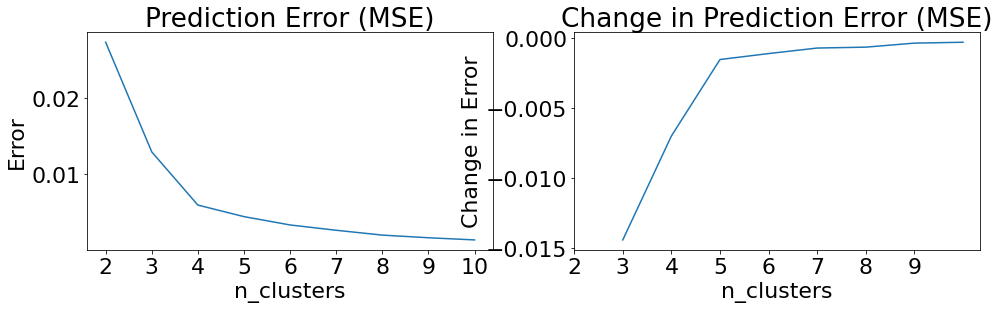
Please choose your final clustering parameters.
Final parameters: {'n_clusters': 4}
CauseClusterer training complete.
Experiment training complete.
Visualize the conditional probability learned by CFL with the optimized hyperparameters
[7]:
from cfl.visualization.cde_diagnostic import pyx_scatter
from importlib import reload
import cfl.visualization.cde_diagnostic as cvc
reload(cvc)
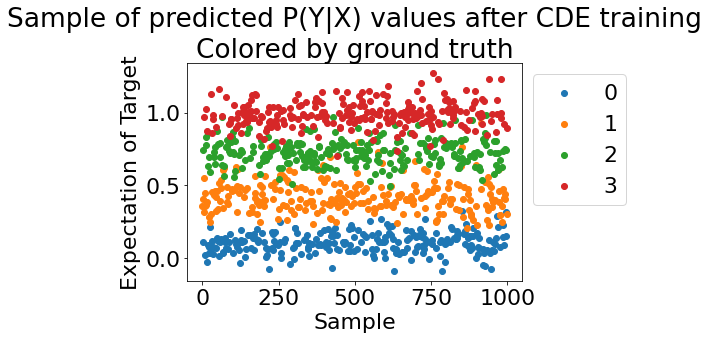
# first by ground truth macrostates
cvc.pyx_scatter(my_exp, vb_data.getGroundTruth(), colored_by='ground truth')
[7]:
(<Figure size 432x288 with 1 Axes>,
<AxesSubplot:title={'center':'Sample of predicted P(Y|X) values after CDE training\nColored by ground truth'}, xlabel='Sample', ylabel='Expectation of Target'>)
[8]:
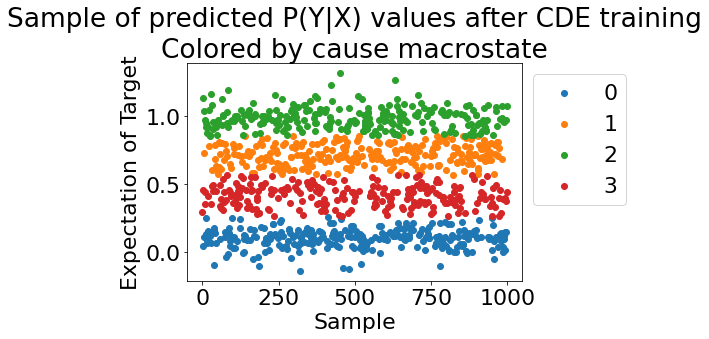
# now color by learned macrostates
cvc.pyx_scatter(my_exp, train_results['CauseClusterer']['x_lbls'],
colored_by='cause macrostate')
[8]:
(<Figure size 432x288 with 1 Axes>,
<AxesSubplot:title={'center':'Sample of predicted P(Y|X) values after CDE training\nColored by cause macrostate'}, xlabel='Sample', ylabel='Expectation of Target'>)
[ ]:
[ ]: